WebP vs. JPEG: Who is the real king?
Currently, image traffic still accounts for a large portion of internet traffic. Therefore, reducing bandwidth usage while maintaining image quality remains an ongoing challenge that needs to be addressed. Traditional image formats such as JPEG, PNG, and GIF have little room left for optimization. Thus, Google introduced a new image compression format, WebP, in 2010, offering new possibilities for image optimization.
WebP: An Upgrade from JPEG
WebP can be seen as an upgraded version of JPEG. Developed by Google, this image file format aims to provide superior lossy and lossless compression for image resources on the web. It delivers smaller yet richer image assets at equivalent quality levels compared to other formats, facilitating faster access and transmission of resources online.
The WebP image format is derived from the VP8 video codec, which is part of the WebM video container—essentially a single compressed frame of the WebM video format. A key capability of the VP8 codec is its support for intra-frame compression, meaning each frame of the video is compressed individually, followed by compression of the differences between consecutive frames.
WebP Features
- Lossy Compression: Built on VP8's core encoding technology. VP8, a video format created by On2 Technologies, is the successor to VP6 and VP7.
- Lossless Compression: Utilizes technologies such as predictive transformation, color transformation, green subtraction, and LZ77 reverse referencing for compression.
- Transparency: An 8-bit Alpha channel, useful for graphic images, which can be used alongside lossy RGB— a unique feature not supported by many other formats.
- Animation: Supports true-color animated images, functioning similarly to GIFs.
- Metadata: Can include EXIF and XMP metadata.
- Color Profiles: May contain embedded ICC profiles.
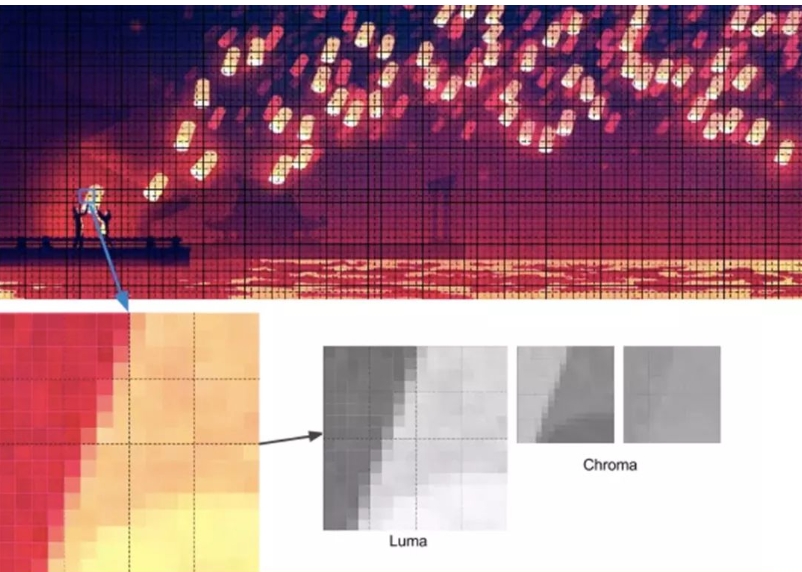
About Compression
Why is lossy compression viable for images? A key principle behind lossy compression is that human perception is less precise than computer processing. Scientific research shows that the human eye can only distinguish about 10 million different colors, and it is more sensitive to brightness than chrominance. This means we often overlook significant chrominance changes without affecting our perception of the image. This phenomenon partly explains the widespread debate over the "black-blue vs. white-gold dress" incident, which was influenced by human visual sensitivity.
Lossy Compression
WebP’s compression uses the same frame prediction method as VP8. Like other block-based codecs, VP8 divides frames into small units called macroblocks. Within each macroblock, the encoder predicts redundant motion and color information based on previously processed blocks. Image frames are "key frames," meaning they only use pixels decoded in the immediate spatial neighborhood of each macroblock and attempt to estimate unknown parts. This is known as predictive coding. Redundant data can then be subtracted from blocks, enabling efficient compression.

Macroblocking
The first stage of the encoder involves dividing the image into "macroblocks." Each macroblock contains a 16x16 luma pixel block and two 8x8 chroma pixel blocks. This stage is similar to JPEG’s process of converting color spaces, downsampling chroma channels, and subdividing images.
Prediction
Each 4x4 sub-block within a macroblock uses a prediction model. It defines two sets of pixels around the block: a row above it (Raw A) and a column to its left (Column L). Using A and L, the encoder fills a 4x4 block of predicted pixels and identifies which prediction most closely matches the original block. These differently filled blocks are called "prediction blocks."
Common block prediction modes include:
- Horizontal Prediction: Each column of the block is a copy of the previous column.
- Vertical Prediction: Each row of the block is filled with a copy of the previous row.
- TM Prediction: A mode based on compression technology developed by On2 Technologies (details to be covered separately).
- DG Prediction: Fills the block with a single value derived from the average of pixels in the row above A and the column left of L.
Notably, 4x4 luma blocks have an additional 6 prediction modes.
The basic process involves finding the most accurate prediction block, deriving filtering results (residual errors), and passing them to the next stage.
Adaptive Quantization
To enhance image quality, the image is divided into regions with distinct similar characteristics. Compression quality is independently adjusted for each region. Efficient compression is achieved by redistributing bits to the most critical areas.
JPGify It
Why is WebP considered an upgrade from JPEG? They share many similarities while outperforming JPEG in certain compression processes.
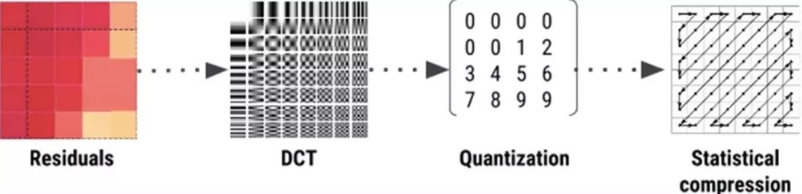
Similarities:
- Apply DCT filtering to residual values within blocks.
- Quantization after the DCT matrix.
- Reorder quantized matrices before sending them to a static compressor.

Differences:
- In the DCT stage, the input data is not the original block itself but post-prediction data.
- WebP uses an arithmetic compressor as its static compressor, similar in function to JPEG’s Huffman encoder but offering 5%–10% better compression performance.
Lossy WebP vs. JPEG
As an upgraded version of JPEG, WebP reduces file size by approximately 50% when compressed to match 90% of the original image quality compared to JPEG. When compressed to 80% quality, WebP reduces file size by 60%–80%. This directly reduces resource size and bandwidth usage.